



星空体育平台官网入口(内附攻略)PC(2024全站)最新版本-IOS/安卓/手机网页版手游下载中心,为玩家推荐新款手机游戏免费下载,星空体育平台官网入口一款能让中华文明传承中医焕发新活力的医疗app,功能简单实用,可以随时随地在手机上学习,还有各种疑难杂症,很容易掌握解题知识。是中医医生、学生、爱好者必备的权威学习工具,严格选择权威数据,全面整理汇编中医经典书籍、医案、方剂。躲避各种危险恐怖的生物,和去在这个异空间中去体验一场危险的恋爱并且成功的生存下来,感兴趣的朋友们千万不要错过哦,快来本站下载体验一下游戏吧!

星空体育平台官网入口(内附攻略)游戏特色
1、在与这些怪人交流的过程中,玩家控制的角色却陷入了一场危险的恋爱!面对一不小心就会死的境地,感受刀尖上舞动的凄美。了解男人的语言并做出正确的选择成为你生存的唯一希望。
2、异空间中,所有的神秘人都使用了一种极其诡异的手段,玩家需要根据这些神秘人的表情、动作、所指的物体等等,来猜测出这些话的真正含义,从而成功地理解他们的意图。
3、在漆黑的异空间,随时可能遇到不同的神秘人,而且并不是个个都是友善的。当危险来临时,你必须做出正确的选择,并不断探索和前行,最终找到逃生之道。
4、🏜【恭喜发财大哥们】🥇🏜【星空体育平台官网入口】⚡️🕯️️⚡️支持:32/64bit⚡️系统类型:星空体育平台官网入口(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《星空体育平台官网入口》阅读模式:新增阅读模式,通过应用优化和调整阅读环境。无论是白天还是夜晚,都能通过阅读模式功能保护眼睛,提升阅读舒适度。
5、🏜【恭喜发财大哥们】🥇🏜【星空体育平台官网入口】⚡️🕯️️⚡️支持:32/64bit⚡️系统类型:星空体育平台官网入口(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《星空体育平台官网入口》字体调整:新增字体大小调整功能,根据个人喜好设置字体大小。无论是视力问题还是阅读习惯,都能找到最适合的字体大小,提升阅读体验。
6、🏜【恭喜发财大哥们】🥇🏜【星空体育平台官网入口】⚡️🕯️️⚡️支持:32/64bit⚡️系统类型:星空体育平台官网入口(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《星空体育平台官网入口》活动日历:新增活动日历功能,通过应用查看和参与各种活动。
7、🏜【恭喜发财大哥们】🥇🏜【星空体育平台官网入口】⚡️🕯️️⚡️支持:32/64bit⚡️系统类型:星空体育平台官网入口(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《星空体育平台官网入口》AR支持:新增增强现实(AR)功能,通过应用体验AR技术。无论是游戏、购物还是学习,都能通过AR支持功能享受更加沉浸的互动体验。。

【河南工会推出首位AI理论宣讲员“豫小宣”******
中工网讯 (工人日报-中工网记者余嘉熙 通讯员王佳宁)近日,河南工会首位AI理论宣讲员“豫小宣”亮相,其身着蓝色工装、语态生动鲜活,在不同场景进行理论宣传、政策解读,构建起全媒体、交互式传播场景,有效提升理论宣讲的感染力和亲和力,让党的创新理论在广大职工群众心中落地生根。
“豫小宣”是基于生成式人工智能技术打造的工会数字人,以AI策划、设计的全新虚拟形象亮相,相较于传统的真人建模数字人,不仅在内容生成速度、灵活性、可持续性、可扩展性等多个维度上展现出显著优势,而且能够迅速响应信息更新,以高效、精准、生动的方式进行宣讲,成为连接工会与职工群众的智能桥梁。
据介绍,“豫小宣”将与河南工会理论宣讲团成员一起进机关、进企业、进社区、进学校、进网络,通过视频、人机对话等新模式,宣讲党的创新理论,讲好新时代劳模故事、劳动故事、工匠故事,增强理论宣讲的吸引力。
为推动新时代工会理论宣讲工作数智化发展,近年来,河南省各级工会坚持“大宣传大宣讲”工作理念,高位推动、创新载体、整合资源,以“中国梦·劳动美”为主线,组织开展多类主题的线上线下宣传教育活动,通过冒热气、接地气、聚人气的宣讲形式,常态化宣讲、专业化领讲、品牌化推广,把党的创新理论送到职工群众心坎里。同时,注重发挥劳动模范、道德模范、大国工匠、最美职工等主体作用,利用云直播、云课堂、AI宣讲等形式,打通线上宣讲渠道,构筑从身边到“指尖”的立体宣讲阵地,让包括新就业形态劳动者、青年职工、农民工在内的广大职工爱看爱听爱学。
今年以来,河南制定印发关于加强和改进新时代理论宣讲工作的实施意见、关于打造河南“中国工人大思政课”的实施方案,建立工作联盟,通过“工会+高校+企业”合作模式搭建思政课互动平台,构建由工会干部、劳模工匠、专家、一线职工组成的工会理论宣讲队伍,聘任首批150位名师,培育一批教育实践阵地、制作一批文创产品,开展河南职工思想政治工作研究和课题申报工作,实施全省工会理论宣讲队伍“个十百千万”工程,绘就全省工会理论宣讲的“路线图”。
领导班子带头讲、劳模专家一线讲、基层工会微宣讲,在河南省总的带动下,多形式、分层次、全覆盖的学习宣讲活动在全省铺开。今年以来,河南各级工会开展各类宣传宣讲活动9700余场,覆盖职工480余万人次,并不断丰富载体,创编文艺作品,连续8年开展万场文化活动进基层,全省今年共开展送文化下基层活动12530余场,受众超150万人次。
】【刷屏的DeepSeek******
每经记者 郑雨航 每经编辑 高涵 兰素英
“DeepSeek-V3超越了迄今为止所有开源模型。”这是国外独立评测机构Artificial Analysis测试了DeepSeek-V3后得出的结论。
12月26日,深度求索官方微信公众号推文称,旗下全新系列模型DeepSeek-V3首个版本上线并同步开源。
公众号推文是这样描述的:DeepSeek-V3为自研MoE模型,671B参数,激活37B,在14.8T token上进行了预训练。DeepSeek-V3多项评测成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,并在性能上和世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。
不过,广发证券发布的测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。
更重要的是,深度求索使用英伟达H800 GPU在短短两个月内就训练出了DeepSeek-V3,仅花费了约558万美元。其训练费用相比GPT-4等大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
消息一出,引发了海外AI圈热议。OpenAI创始成员Karpathy甚至对此称赞道:“DeepSeek-V3让在有限算力预算上进行模型预训练这件事变得容易。DeepSeek-V3看起来比Llama-3-405B更强,训练消耗的算力却仅为后者的1/11。”
然而,在使用过程中,《每日经济新闻》记者发现,DeepSeek-V3竟然声称自己是ChatGPT。一时间,“DeepSeek-V3是否在使用ChatGPT输出内容进行训练”的质疑声四起。
对此,《每日经济新闻》记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得改进。”
每经记者向深度求索公司发出采访请求,截至发稿,尚未收到回复。
针对DeepSeek-V3,独立评测网站Artificial Anlaysis就关键指标——包括质量、价格、性能(每秒生成的Token数以及首个Token生成时间)、上下文窗口等多方面——与其他人工智能模型进行对比,最终得出以下结论。
质量:DeepSeek-V3质量高于平均水平,各项评估得出的质量指数为80。
价格:DeepSeek-V3比平均价格更便宜,每100万个Token的价格为0.48美元。其中,输入Token价格为每100万个Token 0.27美元,输出Token价格为每100万个Token1.10 美元。
速度:DeepSeek-V3比平均速度慢,其输出速度为每秒87.5个Token。
延迟:DeepSeek-V3与平均水平相比延迟更高,接收首个Token(即首字响应时间)需要1.14秒。
上下文窗口:DeepSeek-V3的上下文窗口比平均水平小,其上下文窗口为13万个Token。
最终Artificial Anlaysis得出结论:
“DeepSeek-V3模型超越了迄今为止发布的所有开放权重模型,并且击败了OpenAI的GPT-4o(8月),并接近Anthropic的Claude 3.5 Sonnet(10月)。
DeepSeek-V3的人工智能分析质量指数得分为80,领先于OpenAI的GPT-4o和Meta的Llama 3.3 70B等模型。目前唯一仍然领先于DeepSeek的模型是谷歌的Gemini 2.0 Flash和OpenAI的o1系列模型。领先于阿里巴巴的Qwen2.5 72B,DeepSeek现在是中国的AI领先者。”
12月29日广发证券计算机行业分析师发布研报称:“为了深入探索DeepSeek-V3的能力,我们采用了覆盖逻辑、数学、代码、文本等领域的多个问题对模型进行测试,将其生成结果与豆包、Kimi以及通义千问大模型生成的结果进行比较。”
测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。例如,在密文解码任务中,DeepSeek-V3是唯一给出正确答案的大模型;而在代码生成的任务中,DeepSeek-V3给出的代码注释、算法原理解释以及开发流程的指引是最为全面的。在文本生成和数学计算能力方面,DeepSeek-V3并未展现出明显优于其他大模型之处。
除了能力,DeepSeek-V3最让业内惊讶的是它的低价格和低成本。
《每日经济新闻》记者注意到,亚马逊Claude 3.5 Sonnet模型的API价格为每百万输入tokens 3美元、输出15美元。也就是说,即便是不按照优惠价格,DeepSeek-V3的使用费用也几乎是Claude 3.5 Sonnet的五十三分之一。
相对低廉的价格,得益于DeepSeek-V3的训练成本控制,深度求索在短短两个月内使用英伟达H800 GPU数据中心就训练出了DeepSeek-V3模型,花费了约558万美元。其训练费用相比OpenAI的GPT-4等目前全球主流的大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
DeepSeek“AI界拼多多”也由此得名。
DeepSeek-V3通过数据与算法层面的优化,大幅提升算力利用效率,实现了协同效应。在大规模MoE模型的训练中,DeepSeek-V3采用了高效的负载均衡策略、FP8混合精度训练框架以及通信优化等一系列优化措施,显著降低了训练成本,以及通过优化MoE专家调度、引入冗余专家策略、以及通过长上下文蒸馏提升推理性能。这证明,模型效果不仅依赖于算力投入,即使在硬件资源有限的情况下,依托数据与算法层面的优化创新,仍然可以高效利用算力,实现较好的模型效果。
广发证券分析称,DeepSeek-V3算力成本降低的原因有两点。
第一,DeepSeek-V3采用的DeepSeekMoE是通过参考了各类训练方法后优化得到的,避开了行业内AI大模型训练过程中的各类问题。
第二,DeepSeek-V3采用的MLA架构可以降低推理过程中的kv缓存开销,其训练方法在特定方向的选择也使得其算力成本有所降低。
科技媒体Maginative的创始人兼主编Chris McKay对此评论称,对于人工智能行业来说,DeepSeek-V3代表了一种潜在的范式转变,即大型语言模型的开发方式。这一成就表明,通过巧妙的工程和高效的训练方法,可能无需以前认为必需的庞大计算资源,就能实现人工智能的前沿能力。
他还表示,DeepSeek-V3的成功可能会促使人们重新评估人工智能模型开发的既定方法。随着开源模型与闭源模型之间的差距不断缩小,公司可能需要在一个竞争日益激烈的市场中重新评估他们的策略和价值主张。
不过,广发证券分析师认为,算力依然是推动大模型发展的核心驱动力。DeepSeek-V3的技术路线得到充分验证后,有望驱动相关AI应用的快速发展,应用推理驱动算力需求增长的因素也有望得到增强。尤其在实际应用中,推理过程涉及到对大量实时数据的快速处理和决策,仍然需要强大的算力支持。
在DeepSeek-V3刷屏之际,有一个bug也引发热议。
在试用DeepSeek-V3过程中,《每日经济新闻》记者在对话框中询问“你是什么模型”时,它给出了一个令人诧异的回答:“我是一个名为ChatGPT的AI语言模型,由OpenAl开发。”此外,它还补充说明,该模型是“基于GPT-4架构”。
国内外很多用户也都反映了这一现象。而且,12月27日,Sam Altman发了一个帖文,外媒指出,Altman这篇推文意在暗讽其竞争对手对OpenAI数据的挖掘。
于是,有人就开始质疑:DeepSeek-V3是否是在ChatGPT的输出基础上训练的?为此,《每日经济新闻》向深度求索发出采访请求。截至发稿,尚未收到回复。
针对这种情况产生的原因,每经记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示,他对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得了改进。”
TechCrunch则猜测称,深度求索可能用了包含GPT-4通过ChatGPT生成的文本的公共数据集。“如果DeepSeek-V3是用这些数据进行训练的,那么该模型可能已经记住了GPT-4的一些输出,现在正在逐字反刍它们。”
“显然,该模型(DeepSeek-V3)可能在某些时候看到了ChatGPT的原始反应,但目前尚不清楚从哪里看到的,”伦敦国王学院专门研究人工智能的研究员Mike Cook也指出,“这也可能是个‘意外’。”他进一步解释称,根据竞争对手AI系统输出训练模型的做法可能对模型质量产生“非常糟糕”的影响,因为它可能导致幻觉和误导性答案。
不过,DeepSeek-V3也并非是第一个错误识别自己的模型,谷歌的Gemini等有时也会声称是竞争模型。例如,Gemini在普通话提示下称自己是百度的文心一言聊天机器人。
造成这种情况的原因可能在于,AI公司在互联网上获取大量训练数据,但是,现如今的互联网本就充斥着各种各样用AI生产出来的数据。据外媒估计,到2026年,90%的互联网数据将由AI生成。这种 “污染” 使得从训练数据集中彻底过滤AI输出变得相当困难。
“互联网数据现在充斥着AI输出,”非营利组织AI Now Institute的首席AI科学家Khlaaf表示,基于此,如果DeepSeek部分使用了OpenAI模型进行提炼数据,也不足为奇。
】【刷屏的DeepSeek******
每经记者 郑雨航 每经编辑 高涵 兰素英
“DeepSeek-V3超越了迄今为止所有开源模型。”这是国外独立评测机构Artificial Analysis测试了DeepSeek-V3后得出的结论。
12月26日,深度求索官方微信公众号推文称,旗下全新系列模型DeepSeek-V3首个版本上线并同步开源。
公众号推文是这样描述的:DeepSeek-V3为自研MoE模型,671B参数,激活37B,在14.8T token上进行了预训练。DeepSeek-V3多项评测成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,并在性能上和世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。
不过,广发证券发布的测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。
更重要的是,深度求索使用英伟达H800 GPU在短短两个月内就训练出了DeepSeek-V3,仅花费了约558万美元。其训练费用相比GPT-4等大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
消息一出,引发了海外AI圈热议。OpenAI创始成员Karpathy甚至对此称赞道:“DeepSeek-V3让在有限算力预算上进行模型预训练这件事变得容易。DeepSeek-V3看起来比Llama-3-405B更强,训练消耗的算力却仅为后者的1/11。”
然而,在使用过程中,《每日经济新闻》记者发现,DeepSeek-V3竟然声称自己是ChatGPT。一时间,“DeepSeek-V3是否在使用ChatGPT输出内容进行训练”的质疑声四起。
对此,《每日经济新闻》记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得改进。”
每经记者向深度求索公司发出采访请求,截至发稿,尚未收到回复。
针对DeepSeek-V3,独立评测网站Artificial Anlaysis就关键指标——包括质量、价格、性能(每秒生成的Token数以及首个Token生成时间)、上下文窗口等多方面——与其他人工智能模型进行对比,最终得出以下结论。
质量:DeepSeek-V3质量高于平均水平,各项评估得出的质量指数为80。
价格:DeepSeek-V3比平均价格更便宜,每100万个Token的价格为0.48美元。其中,输入Token价格为每100万个Token 0.27美元,输出Token价格为每100万个Token1.10 美元。
速度:DeepSeek-V3比平均速度慢,其输出速度为每秒87.5个Token。
延迟:DeepSeek-V3与平均水平相比延迟更高,接收首个Token(即首字响应时间)需要1.14秒。
上下文窗口:DeepSeek-V3的上下文窗口比平均水平小,其上下文窗口为13万个Token。
最终Artificial Anlaysis得出结论:
“DeepSeek-V3模型超越了迄今为止发布的所有开放权重模型,并且击败了OpenAI的GPT-4o(8月),并接近Anthropic的Claude 3.5 Sonnet(10月)。
DeepSeek-V3的人工智能分析质量指数得分为80,领先于OpenAI的GPT-4o和Meta的Llama 3.3 70B等模型。目前唯一仍然领先于DeepSeek的模型是谷歌的Gemini 2.0 Flash和OpenAI的o1系列模型。领先于阿里巴巴的Qwen2.5 72B,DeepSeek现在是中国的AI领先者。”
12月29日广发证券计算机行业分析师发布研报称:“为了深入探索DeepSeek-V3的能力,我们采用了覆盖逻辑、数学、代码、文本等领域的多个问题对模型进行测试,将其生成结果与豆包、Kimi以及通义千问大模型生成的结果进行比较。”
测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。例如,在密文解码任务中,DeepSeek-V3是唯一给出正确答案的大模型;而在代码生成的任务中,DeepSeek-V3给出的代码注释、算法原理解释以及开发流程的指引是最为全面的。在文本生成和数学计算能力方面,DeepSeek-V3并未展现出明显优于其他大模型之处。
除了能力,DeepSeek-V3最让业内惊讶的是它的低价格和低成本。
《每日经济新闻》记者注意到,亚马逊Claude 3.5 Sonnet模型的API价格为每百万输入tokens 3美元、输出15美元。也就是说,即便是不按照优惠价格,DeepSeek-V3的使用费用也几乎是Claude 3.5 Sonnet的五十三分之一。
相对低廉的价格,得益于DeepSeek-V3的训练成本控制,深度求索在短短两个月内使用英伟达H800 GPU数据中心就训练出了DeepSeek-V3模型,花费了约558万美元。其训练费用相比OpenAI的GPT-4等目前全球主流的大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
DeepSeek“AI界拼多多”也由此得名。
DeepSeek-V3通过数据与算法层面的优化,大幅提升算力利用效率,实现了协同效应。在大规模MoE模型的训练中,DeepSeek-V3采用了高效的负载均衡策略、FP8混合精度训练框架以及通信优化等一系列优化措施,显著降低了训练成本,以及通过优化MoE专家调度、引入冗余专家策略、以及通过长上下文蒸馏提升推理性能。这证明,模型效果不仅依赖于算力投入,即使在硬件资源有限的情况下,依托数据与算法层面的优化创新,仍然可以高效利用算力,实现较好的模型效果。
广发证券分析称,DeepSeek-V3算力成本降低的原因有两点。
第一,DeepSeek-V3采用的DeepSeekMoE是通过参考了各类训练方法后优化得到的,避开了行业内AI大模型训练过程中的各类问题。
第二,DeepSeek-V3采用的MLA架构可以降低推理过程中的kv缓存开销,其训练方法在特定方向的选择也使得其算力成本有所降低。
科技媒体Maginative的创始人兼主编Chris McKay对此评论称,对于人工智能行业来说,DeepSeek-V3代表了一种潜在的范式转变,即大型语言模型的开发方式。这一成就表明,通过巧妙的工程和高效的训练方法,可能无需以前认为必需的庞大计算资源,就能实现人工智能的前沿能力。
他还表示,DeepSeek-V3的成功可能会促使人们重新评估人工智能模型开发的既定方法。随着开源模型与闭源模型之间的差距不断缩小,公司可能需要在一个竞争日益激烈的市场中重新评估他们的策略和价值主张。
不过,广发证券分析师认为,算力依然是推动大模型发展的核心驱动力。DeepSeek-V3的技术路线得到充分验证后,有望驱动相关AI应用的快速发展,应用推理驱动算力需求增长的因素也有望得到增强。尤其在实际应用中,推理过程涉及到对大量实时数据的快速处理和决策,仍然需要强大的算力支持。
在DeepSeek-V3刷屏之际,有一个bug也引发热议。
在试用DeepSeek-V3过程中,《每日经济新闻》记者在对话框中询问“你是什么模型”时,它给出了一个令人诧异的回答:“我是一个名为ChatGPT的AI语言模型,由OpenAl开发。”此外,它还补充说明,该模型是“基于GPT-4架构”。
国内外很多用户也都反映了这一现象。而且,12月27日,Sam Altman发了一个帖文,外媒指出,Altman这篇推文意在暗讽其竞争对手对OpenAI数据的挖掘。
于是,有人就开始质疑:DeepSeek-V3是否是在ChatGPT的输出基础上训练的?为此,《每日经济新闻》向深度求索发出采访请求。截至发稿,尚未收到回复。
针对这种情况产生的原因,每经记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示,他对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得了改进。”
TechCrunch则猜测称,深度求索可能用了包含GPT-4通过ChatGPT生成的文本的公共数据集。“如果DeepSeek-V3是用这些数据进行训练的,那么该模型可能已经记住了GPT-4的一些输出,现在正在逐字反刍它们。”
“显然,该模型(DeepSeek-V3)可能在某些时候看到了ChatGPT的原始反应,但目前尚不清楚从哪里看到的,”伦敦国王学院专门研究人工智能的研究员Mike Cook也指出,“这也可能是个‘意外’。”他进一步解释称,根据竞争对手AI系统输出训练模型的做法可能对模型质量产生“非常糟糕”的影响,因为它可能导致幻觉和误导性答案。
不过,DeepSeek-V3也并非是第一个错误识别自己的模型,谷歌的Gemini等有时也会声称是竞争模型。例如,Gemini在普通话提示下称自己是百度的文心一言聊天机器人。
造成这种情况的原因可能在于,AI公司在互联网上获取大量训练数据,但是,现如今的互联网本就充斥着各种各样用AI生产出来的数据。据外媒估计,到2026年,90%的互联网数据将由AI生成。这种 “污染” 使得从训练数据集中彻底过滤AI输出变得相当困难。
“互联网数据现在充斥着AI输出,”非营利组织AI Now Institute的首席AI科学家Khlaaf表示,基于此,如果DeepSeek部分使用了OpenAI模型进行提炼数据,也不足为奇。
】【交错战线周年自选6⭐推荐******
交错战线周年自选6⭐推荐如下:
周年庆自选6⭐选取,首先就是,拿到先不要用,等抽完定制卡池再补缺。
纯辅助:
乌琳-打火再动加攻治疗
芭音-拉条打火加攻治疗
袅韵-治疗解控打火加攻
一般来说,袅韵适合中后期活动高难本,乌琳/芭音适合任何时间段。作者3个都80级了,目前满特性袅韵只在高难活动本上场,如果是反击队提尔锋时期入坑,还是先选袅韵比较好。
纯输出:
赤溟-半年限定
黑兔-核爆艺术
赤溟是半周年限定,强度也在线。如果有赤溟选项,闭着眼选赤溟,毕竟下次复刻不知道什么时候了。
黑兔乌斯怀亚是核爆队的核心,秒天秒地秒空气,有了黑兔,10回合?不!6回合干趴BOSS!尤其是这次白兔复刻来个黑白配,谁不迷糊。
阵容核心补缺:
卡提那-协击核心
提尔锋-反击核心
C.C.C.-虫洞核心
巴德-不朽减防
什么,你问我怎么用?全角色老登为啥要用,当然是拿来收藏了
最后统一回复一下即将入坑的萌新入坑时间:周年庆一定要入坑,最好自建号。赤溟肯定复刻,指不定自选里面就有。这游戏不缺抽卡券,自建号安全,搞个4万聚宝盆美滋滋,立省大几千。
】【北方多地将度过下半年来最冷白天******
北方多地将度过下半年来最冷白天 明起中东部开启升温模式
中国天气网讯 今后三天(12月27日至29日),全国大部继续维持晴朗干燥的天气格局,西藏、青海南部有一次降雪过程,并伴有大风天气。眼下,冷空气对中东部的影响还在持续,长江以北部分地区气温或创今年下半年来新低,明天起大江南北将陆续迎来升温。
全国大部晴朗天气居多 西藏青海降雪发展
近期,全国大部降水稀少,多地午后最小相对湿度不足30%,广西、广东、福建一带出现中度以上气象干旱。今后三天,全国大部晴朗天气依然唱主调,随着南支槽东移,西藏、青海南部将自西向东有一次降雪过程,降雪期间,西藏的阿里、那曲和日喀则大部还将出现7至8级大风,阵风可达9至10级。
中央气象台预计,今天,西藏西部、新疆西南部、川西高原东部、贵州西部、内蒙古东北部等地部分地区有小雪或雨夹雪,其中,西藏西部部分地区有中到大雪,局地暴雪。湖北西南部、四川盆地南部、重庆中部、贵州东北部和西部、云南东部、广西西北部、海南岛中东部、台湾岛等地部分地区有小雨。

明天,新疆北疆北部和南疆盆地南部山区、西藏西北部和南部、青海南部和西部等地部分地区有小到中雪,其中,西藏南部和西部等地部分地区有大到暴雪。云南西南部和中部、台湾岛东部等地部分地区有小雨。

后天,内蒙古东北部、西藏北部和东部、青海南部和西部、甘肃南部、川西高原北部等地部分地区有小雪或雨夹雪,其中,西藏东部、青海南部、甘肃南部、川西高原北部等地部分地区有中到大雪,西藏东部等地局地暴雪。西藏东南部、四川盆地东南部、重庆中西部、贵州西北部、台湾岛东部等地部分地区有小雨。
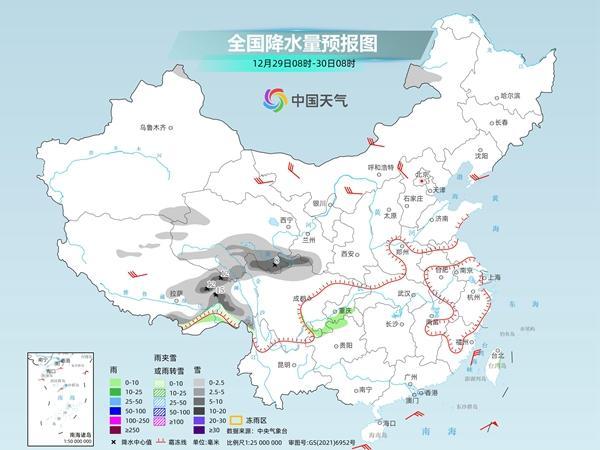
中国天气网提醒,这次降雪过程可能给西藏南部部分地区带来5至10厘米的新增积雪,局地可达30厘米以上,公众需注意防范积雪、风吹雪、大风等对交通出行、农牧业等方面的不利影响。此外,中东部干燥天气持续,且随着干冷的偏北风南下控场,华北、黄淮等地干燥程度还会加剧,江南、华南多地湿度也会随之下降,大家需及时补充水分,多吃银耳、雪梨等食物缓解干燥。
今天中东部多地气温继续下降 明起陆续迎来升温
今天,冷空气继续南下,中东部多地将出现降温,气温将短暂转为较常年同期偏低的状态,长江以北部分地区还可能度过下半年来最冷的白天。城市中,兰州今天最高气温零下3℃,可能创下半年来气温新低。
明天起,北方大部将开启升温模式,南方则在后天步入升温通道。2024年尾声,全国大部气温将较常年同期偏高,其中华北至华南北部气温普遍会偏高5℃左右。总体来看,未来几天晴朗升温是“主旋律”,大家不妨在中午时段适当进行户外活动。
来源:中国天气网
】星空体育平台官网入口(内附攻略)游戏下载方式
第一步:选择/拖拽文件至软件中
点击“添加星空体育平台官网入口”按钮从电脑文件夹选择文件,或者直接拖拽文件到软件界面。
第二步:选择需要转换的文件格式 打开软件界面选择你需要的功能,星空体育平台官网入口支持,PDF互转Word,PDF互转Excel,PDF互转PPT,PDF转图片等。
第三步:点击【开始转换】按钮点击“开始转换”按钮, 开始文件格式转换。等待转换成功后,即可打开文件。三步操作,顺利完成文件格式的转换。。
👇欢迎使用星空体育平台官网入口官网-APP下载🏊注册送好礼🎁注册教程七步
👇步骤1:访问 星空体育平台官网入口官网 | 登录入口 首先,打开您的浏览器,输入🕰星空体育平台官网入口🥇的官方网址【http://www.www.chongqing.bjssckj.cn/rko/down/zzsgmnqy.html】进入官网或者打开软件登录界面。 可以通过浏览器🫚步骤2:点击注册按钮 一旦进入 星空体育平台官网入口官网,您会在页面上找到一个醒目的注册按钮。点击该按钮,您将被引导至注册页面。
🎪️步骤3:填写注册信息 在注册页面上,您需要填写一些必要的个人信息来创建 星空体育平台官网入口账户。通常包括用户名、密码、电子邮件地址、手机号码等。请务必提供
🚿步骤4:验证账户填写完个人信息后,您可能需要进行账户验证。🦆星空体育平台官网入口🛁会向您提供的电子邮件地址或手机号码发送一条验证信息,您需要按照提示进行验证操作。这有助于确保账户的安全性,并防止不法分子滥用您的个人信息。
🤼步骤5:设置安全选项🍍星空体育平台官网入口📴通常要求您设置一些安全选项,以增强账户的安全性。例如,可以设置安全问题和答案,启用两步验证等功能。请根据系统的提示设置相关选项,并妥善保管相关信息,确保您的账户安全。
🧯步骤6:阅读并同意条款在注册过程中,🔮星空体育平台官网入口🍋会提供使用条款和规定供您阅读。这些条款包括平台的使用规范、隐私政策等内容。在注册之前,请仔细阅读并理解这些条款,并确保您同意并愿意遵守。
🥙步骤7:完成注册一旦您完成了所有必要的步骤,并同意了🐱星空体育平台官网入口🕸的条款,恭喜您!您已经成功注册了🍘

星空体育平台官网入口(内附攻略)游戏亮点
1、任务
音乐识别:新增音乐识别功能,通过应用识别和查找正在播放的音乐。无论是商店里还是车里,都能通过音乐识别功能快速找到歌曲,提升音乐体验。
2、副本
字体库:新增字体库功能,通过应用下载和使用各种字体。无论是设计工作还是个性化设置,都能通过字体库功能找到合适的字体,提升美感。
3、解密
自动化:支持更多自动化操作,通过应用自动完成任务。无论是定时操作还是条件触发,都能通过自动化功能提升效率,解放双手。
4、日语
用户等级:新增用户等级和奖励系统,根据使用情况提升等级。无论是活跃度还是贡献度,都能获得相应的奖励,激励用户积极参与应用活动。
5、气氛
定制推荐:根据用户习惯推荐个性化内容,无论是新闻、视频还是商品,都能根据你的兴趣智能推荐,让你发现更多感兴趣的内容。

配置要求
最低配置
操作系统:Windows 7或以上
CPU:Intel i5 Quad-Core
内存:4 GB RAM
显卡:NVIDIA GeForce GTX 750 Ti
存储空间:需要 2 GB 可用空间
上一篇:开yun体育app入口登录
下一篇:最后一页
 壹号娱乐
壹号娱乐 星空体育app官方下载
星空体育app官方下载 开元棋app官方下载
开元棋app官方下载 开元棋盘财神捕鱼官网版下载2023
开元棋盘财神捕鱼官网版下载2023 开yun体育app官方下载入口
开yun体育app官方下载入口 星空体育官方网站
星空体育官方网站 南宫28ng娱乐平台游戏特色
南宫28ng娱乐平台游戏特色 开元棋盘财神捕鱼官网版下载2023
开元棋盘财神捕鱼官网版下载2023 pg电子赏金试玩app
pg电子赏金试玩app 南宫ng注册平台入口
南宫ng注册平台入口 kaiyun全站登录网页入口
kaiyun全站登录网页入口 kai云体育app官网版下载
kai云体育app官网版下载 kaiyun全站app登录入口
kaiyun全站app登录入口 云开·全站app登录网页入口
云开·全站app登录网页入口 c7官网app下载安装
c7官网app下载安装 爱游戏官方网站入口登录手机版
爱游戏官方网站入口登录手机版 开yun体育官网入口登录体育
开yun体育官网入口登录体育 大小单双赚钱平台
大小单双赚钱平台 爱游戏官方网站入口登录手机版
爱游戏官方网站入口登录手机版 云开·全站app中心手机版
云开·全站app中心手机版 kaiyun云开网页版登录入口登录
kaiyun云开网页版登录入口登录 开yunapp体育官网入口下载手机版
开yunapp体育官网入口下载手机版 开元棋盘财神捕鱼官网版下载2023
开元棋盘财神捕鱼官网版下载2023 kai云体育app官网版下载
kai云体育app官网版下载 澳门威尼克斯人网站
澳门威尼克斯人网站 金沙棋牌js6666手机版
金沙棋牌js6666手机版 壹号娱乐
壹号娱乐 ng28.666官网版
ng28.666官网版 九游体育
九游体育 开yun体育官网入口登录体育
开yun体育官网入口登录体育 ng28.666南宫娱乐官网下载
ng28.666南宫娱乐官网下载 kaiyun云开网页版登录入口登录
kaiyun云开网页版登录入口登录 爱游戏app最新官网登录
爱游戏app最新官网登录 ng南宫国际app下载
ng南宫国际app下载 问鼎app官方下载
问鼎app官方下载 云开·全站app中心手机版
云开·全站app中心手机版 熊猫体育
熊猫体育 九游体育
九游体育 星空体育官方网站
星空体育官方网站 开元棋官方正版下载
开元棋官方正版下载 kai云体育app官网版下载
kai云体育app官网版下载 九游体育
九游体育 澳门威尼克斯人网站
澳门威尼克斯人网站 九游体育
九游体育 开yun体育官网入口登录app
开yun体育官网入口登录app ng南宫国际app下载
ng南宫国际app下载 熊猫体育
熊猫体育 pg免费游戏试玩模拟器
pg免费游戏试玩模拟器 pg麻将胡了试玩平台
pg麻将胡了试玩平台 九游体育
九游体育 kaiyun全站app登录入口
kaiyun全站app登录入口 c7娱乐电子游戏官网
c7娱乐电子游戏官网 pg赏金女王单机版试玩平台
pg赏金女王单机版试玩平台 爱游戏app官方网站登录入口
爱游戏app官方网站登录入口 c7官网app下载安装
c7官网app下载安装 pg棋牌
pg棋牌 九游娱乐
九游娱乐 kaiyun云开网页版登录入口登录
kaiyun云开网页版登录入口登录 j9九游真人游戏第一平台
j9九游真人游戏第一平台 kaiyun官方网站登录入口
kaiyun官方网站登录入口 爱游戏官方网站入口登录手机版
爱游戏官方网站入口登录手机版 c7官网app下载安装
c7官网app下载安装 j9九游真人游戏第一平台
j9九游真人游戏第一平台 问鼎娱乐
问鼎娱乐 澳门威尼克斯人网站
澳门威尼克斯人网站 开元棋盘app官方版下载_开元棋盘app官网版下载-跑跑车
开元棋盘app官方版下载_开元棋盘app官网版下载-跑跑车 美高梅棋牌官网入口
美高梅棋牌官网入口 lol押注正规平台官网
lol押注正规平台官网 大小单双赚钱平台
大小单双赚钱平台 鼎盛注册平台
鼎盛注册平台 kaiyun全站app登录入口
kaiyun全站app登录入口 澳门新莆京游戏app大厅
澳门新莆京游戏app大厅 威尼斯wns.8885556
威尼斯wns.8885556 爱游戏app官方入口最新版本
爱游戏app官方入口最新版本 爱游戏app最新官网登录
爱游戏app最新官网登录 星空综合体育app下载
星空综合体育app下载 模拟器pg麻将胡了
模拟器pg麻将胡了 南宫ng注册平台入口
南宫ng注册平台入口 星空综合体育app下载
星空综合体育app下载 j9九游真人游戏第一平台
j9九游真人游戏第一平台 pg麻将胡了试玩平台
pg麻将胡了试玩平台 云开·全站app登录网页入口
云开·全站app登录网页入口 澳门威尼克斯人网站
澳门威尼克斯人网站 pg麻将胡了试玩平台
pg麻将胡了试玩平台